
By Michael Arsenault, Director of Product Marketing for AEC DSPs, Marvell
Rack connectivity is undergoing a historic transformation. Data center operators are demanding both scale-up and scale-out connectivity that can move more data across longer distances and between more systems, while delivering unprecedented levels of energy efficiency and reliability.
To help cable providers and their customers meet these challenges, Marvell has launched the Golden Cable initiative, designed to accelerate the development of active electrical cables (AECs). AECs are a rapidly growing class of high-bandwidth, enhanced copper interconnects used to link servers, switches, NICs and other assets in the same rack or across adjacent racks (about two to nine meters).
The Golden Cable initiative delivers a validated cable architecture tested across leading platforms and built on industry-leading software, reference designs, technical data, firmware and comprehensive support. Participants can combine these assets with their own technology to develop unique AECs powered by DSPs, optimized for specific customer requirements and use cases.
To further enhance performance and ensure broad compatibility, Golden Cable AECs are rigorously tested in the Marvell Cloud Interoperability Lab. Here, cables are validated across a wide range of customized configuration scenarios involving leading XPUs, CPUs, NICs, servers, switches, optical modules and other critical infrastructure components. This process enables Marvell and its partners to validate AEC firmware before cables reach end-customers, significantly accelerating customer qualification and deployment timelines. The result is greater confidence from the first plug-in.
By Khurram Malik, Senior Director of Marketing, Custom Cloud Solutions, Marvell
Can AI beat a human at the game of twenty questions? Yes.
And can a server enhanced by CXL beat an AI server without it? Yes, and by a wide margin.
While CXL technology was originally developed for general-purpose cloud servers, the technology is now finding a home in AI as a vehicle for economically and efficiently boosting the performance of AI infrastructure. To this end, Marvell has been conducting benchmark tests on different AI use cases.
In December, Marvell, Samsung and Liqid showed how Marvell® StructeraTM A CXL compute accelerators can reduce the time required for conducting vector searches (for analyzing unstructured data within documents) by more than 5x.
In February, Marvell showed how a trio of Structera A CXL compute accelerators can process more queries per second than a cutting-edge server CPU and at a lower latency while leaving the host CPU open for different computing tasks.
Today, this blog post will show how Structera CXL memory expanders can boost performance of inference tasks.
AI and Memory Expansion
Unlike CXL compute accelerators, CXL memory expanders do not contain additional processing cores for near-memory computing. Instead, they supersize memory capacity and bandwidth. Marvell Structera X, released last year, provides a path for adding up to 4TB of DDR5 DRAM or 6TB of DDR4 DRAM to servers (12TB with integrated LZ4 compression) along with 200GB/second of additional bandwidth. Multiple Structera X modules, moreover, can be added to a single server; CXL modules slot into PCIe ports rather than the more limited DIMM slots used for memory.

By Khurram Malik, Senior Director of Marketing, Custom Cloud Solutions, Marvell
While CXL technology was originally developed for general-purpose cloud servers, it is now emerging as a key enabler for boosting the performance and ROI of AI infrastructure.
The logic is straightforward. Training and inference require rapid access to massive amounts of data. However, the memory channels on today’s XPUs and CPUs struggle to keep pace, creating the so-called “memory wall” that slows processing. CXL breaks this bottleneck by leveraging available PCIe ports to deliver additional memory bandwidth, expand memory capacity and, in some cases, integrate near-memory processors. As an added advantage, CXL provides these benefits at a lower cost and lower power profile than the usual way of adding more processors.
To showcase these benefits, Marvell conducted benchmark tests across multiple use cases to demonstrate how CXL technology can elevate AI performance.
In December, Marvell and its partners showed how Marvell® StructeraTM A CXL compute accelerators can reduce the time required for vector searches used to analyze unstructured data within documents by more than 5x.
Here’s another one: CXL is deployed to lower latency.
Lower Latency? Through CXL?
At first glance, lower latency and CXL might seem contradictory. Memory connected through a CXL device sits farther from the processor than memory connected via local memory channels. With standard CXL devices, this typically results in higher latency between CXL memory and the primary processor.

Marvell Structera A CXL memory accelerator boards with and without heat sinks.
By Sandeep Bharathi, president, Data Center Group, Marvell
This blog was originally posted at Fortune.
Semiconductors have transformed virtually every aspect of our lives. Now, the semiconductor industry is on the verge of a profound transformation itself.
Customized silicon—chips uniquely tailored to meet the performance and power requirements of an individual customer for a particular use case—will increasingly become pervasive as data center operators and AI developers seek to harness the power of AI. Expanded educational opportunities, better decision making, ways to improve the sustainability of the planet all become possible if we get the computational infrastructure right.
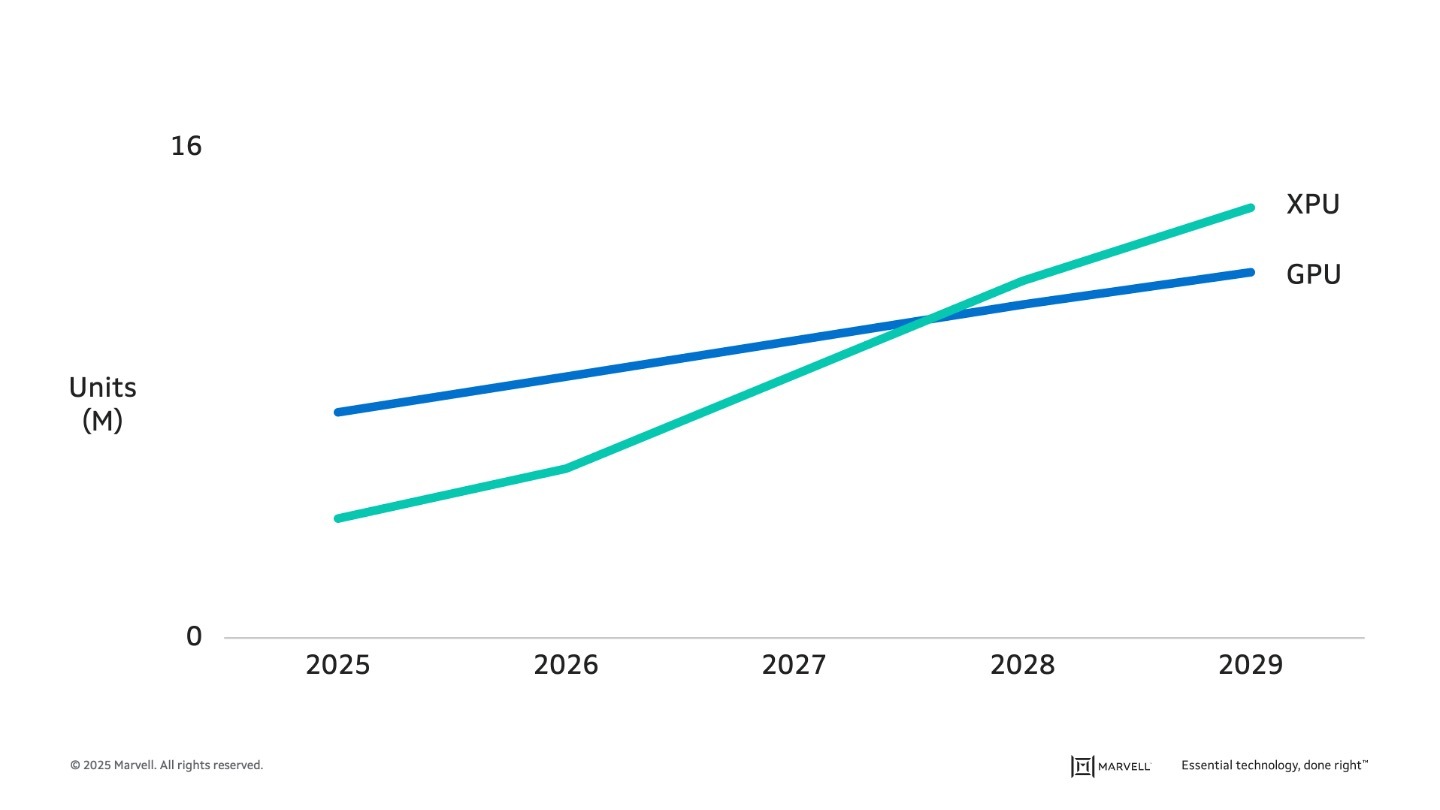
The turn to custom, in fact, is already underway. The number of GPUs—the merchant chips employed for AI training and inference—produced today is nearly double the number of custom XPUs built for the same tasks. By 2028, custom accelerators will likely pass GPUs in units shipped, with the gap expected to grow.1
By Michael Kanellos, Head of Influencer Relations, Marvell
The opportunity for custom silicon isn’t just getting larger – it’s becoming more diverse.
At the Custom AI Investor Event, Marvell executives outlined how the push to advance accelerated infrastructure is driving surging demand for custom silicon – reshaping the customer base, product categories and underlying technologies. (Here is a link to the recording and presentation slides.)
Data infrastructure spending is now slated to surpass $1 trillion by 20281 with the Marvell total addressable market (TAM) for data center semiconductors rising to $94 billion by then, 26% larger than the year before. Of that total, $55.4 billion revolves around custom devices for accelerated compute1. In fact, the forecast for every major product segment has risen in the past year, underscoring the growing momentum behind custom silicon.

The deeper you go into the numbers, the more compelling the story becomes. The custom market is evolving into two distinct elements: the XPU segment, focused on optimized CPUs and accelerators, and the XPU attach segment that includes PCIe retimers, co-processors, CPO components, CXL controllers and other devices that serve to increase the utilization and performance of the entire system. Meanwhile, the TAM for custom XPUs is expected to reach $40.8 billion by 2028, growing at a 47% CAGR1.